LRML 구현
부스트캠프 movie recommendation 프로젝트 과정에서 진행한, LRML 논문 구현에 관한 글이다.
Papers with code 페이지에서 Movie Lens 에서 성능이 높은 모델을 직접 구현해봤다.
LRML이 Movie Lens 1M, 20M 데이터에서 HR@10 이 각각 5위, 2위로 높은 성능을 보여서 채택했다. 뒤에서 설명하겠지만, Movie Lens 데이터에 대한 성능이 충분한 근거는 되지 못한 것 같다.
Metric Learning은 거리 공간에 벡터로 나타내는 임베딩을 학습하는 방법이다. 이 공간에 유사한 벡터들의 metric을 올리고, 유사하지 않은 벡터들의 metric을 낮추는 방향으로 학습한다.
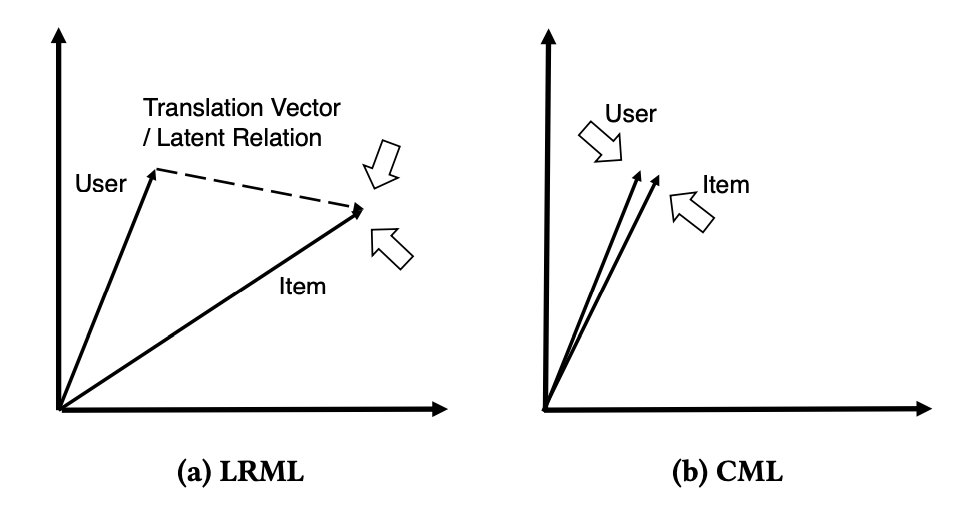
출처: Latent Relational Metric Learning via Memory-based Attention for Collaborative Ranking
LRML 모델은 유저-아이템 사이의 거리를 학습하면서, 동시에 유저, 아이템의 관계 벡터를 학습한다. 관계 벡터는 유저-아이템 벡터의 hadamard product 값을 input으로 하는 Latent Relational Attentive Memory (LRAM) 모듈에서 학습되고, 유저, 아이템 벡터와 동일한 차원의 벡터이다.
각 아이템-유저 벡터의 거리는 \(\|\|p+r-q\|\|^2_2\) 로 계산되고, 최종 Loss는 다음과 같이 계산된다.
\[L=\sum_{(p, q) \in \Delta} \sum_{\left(p^{\prime}, q^{\prime}\right) \notin \Delta} \max \left(0, s(p, q)+\lambda-s\left(p^{\prime}, q^{\prime}\right)\right)\]최종 loss도 미분이 가능하기 때문에, end-to-end로 학습이 가능하다.
import torch.nn as nn
import torch
import torch.nn.functional as F
class LRML(nn.Module):
"""
Latent Relational Metric Learning (LRML) 모델 클래스.
논문 참고: https://arxiv.org/pdf/1707.05176
Args:
num_users (int): 사용자 수.
num_items (int): 아이템 수.
embedding_dim (int): 임베딩 벡터의 차원.
memory_size (int): 메모리 크기.
margin (float, optional): 랭킹 손실을 위한 마진. 기본값은 0.2.
reg_weight (float, optional): L2 손실을 위한 정규화 가중치. 기본값은 0.1.
Attributes:
user_embedding (nn.Embedding): 사용자 임베딩 레이어.
item_embedding (nn.Embedding): 아이템 임베딩 레이어.
key_layer (nn.Parameter): 메모리 어텐션을 위한 키 레이어.
memory (nn.Parameter): 메모리 매트릭스.
margin (float): 랭킹 손실을 위한 마진.
reg_weight (float): L2 손실을 위한 정규화 가중치.
interaction_matrix (torch.Tensor): 상호작용 매트릭스 버퍼.
Methods:
forward(users, items, relation=None):
사용자-아이템 쌍에 대한 점수를 계산하는 순전파.
get_relation(users, items):
사용자-아이템 쌍에 대한 관계 벡터를 계산.
training_step(users, items, neg_users, neg_items):
사용자-아이템 및 부정 사용자-아이템 쌍의 배치에 대한 학습 손실을 계산.
_clip_by_norm(tensor, max_norm):
텐서를 L2 노름으로 클리핑.
"""
def __init__(self, num_users, num_items, embedding_dim, memory_size, margin=0.2, reg_weight = 0.1):
super().__init__()
self.user_embedding = nn.Embedding(num_users, embedding_dim)
self.item_embedding = nn.Embedding(num_items, embedding_dim)
self.key_layer = nn.Parameter(torch.randn(embedding_dim, memory_size))
self.memory = nn.Parameter(torch.randn(memory_size, embedding_dim))
self.margin = margin
self.reg_weight = reg_weight
self.register_buffer('interaction_matrix', None)
# 임베딩 초기화
nn.init.normal_(self.user_embedding.weight, std=0.01)
nn.init.normal_(self.item_embedding.weight, std=0.01)
nn.init.normal_(self.key_layer, std=0.01)
nn.init.normal_(self.memory, std=0.01)
def forward(self, users, items, relation=None):
# 임베딩 검색
user_embed = self.user_embedding(users)
item_embed = self.item_embedding(items)
user_embed = self._clip_by_norm(user_embed, 2.0) # (batch_size, embed_dim)
item_embed = self._clip_by_norm(item_embed, 2.0) # (batch_size, embed_dim)
if relation is not None:
user_translated = user_embed + relation
else:
user_translated = user_embed + self.get_relation(users, items)
scores = -torch.sqrt(torch.sum((user_translated - item_embed).pow(2), dim=-1) + 1e-3) # (batch_size,)
return scores
def get_relation(self, users, items):
# 임베딩 검색
user_embed = self.user_embedding(users)
item_embed = self.item_embedding(items)
user_embed = self._clip_by_norm(user_embed, 2.0) # (batch_size, embed_dim)
item_embed = self._clip_by_norm(item_embed, 2.0) # (batch_size, embed_dim)
# User-Item Pair에 대한 Interaction 및 Relation 계산
interaction = user_embed * item_embed # (batch_size, embed_dim)
keys = torch.matmul(interaction, self.key_layer) # (batch_size, memory_size)
attention = torch.softmax(keys, dim=-1) # (batch_size, memory_size)
# Pair-based Relation vector 계산
relation = torch.matmul(attention, self.memory) # (batch_size, embed_dim)
return relation
def training_step(self, users, items, neg_users, neg_items):
relation = self.get_relation(users, items)
pos_scores = self.forward(users, items, relation)
neg_scores = self.forward(neg_users, neg_items, relation)
loss = torch.sum(F.relu(self.margin - pos_scores + neg_scores))
l2_loss = 0
for param in self.parameters():
l2_loss += torch.norm(param, p=2)
return loss + l2_loss * self.reg_weight
def _clip_by_norm(self, tensor, max_norm):
norm = torch.norm(tensor, p=2, dim=-1, keepdim=True) # L2 노름 계산
factor = torch.clamp(max_norm / (norm + 1e-6), max=1.0)
return tensor * factor